Publish and synchronize: Advanced use cases
Edit on GitHubData synchronization is essential for maintaining consistency and enabling seamless data exchange in distributed systems. Spryker addresses these challenges through its Publish & Synchronize (P&S) mechanism. This guide explains how P&S works and explores common scenarios where manual intervention or configuration may be required.
Repeated export: re-publishing or re-synchronize data
In Spryker, the Glue API and Yves retrieve product information from Redis and Elasticsearch. After a product catalog update, the storefront may occasionally display outdated data. This typically happens when Redis and Elasticsearch are out of sync. In this case, you can use repeated export to sync data.
Repeated export is also helpful in scenarios such as the following:
-
Search index rebuilding
-
Data model structure changes
-
Data corruption or inconsistencies
-
When making direct changes to product data (not recommended), such as listings, prices, or availability
To resolve this, you can re-export published data, or manually trigger data re-publication.
For detailed steps, see Re-synchronization and re-generation.
Replacing key-value storage with a database
P&S creates expected data duplication: the same data is stored both in the database and key-value storage. In high-load scenarios, like B2C, where there is usually a large number of customers, such data duplication is necessary to ensure performance when processing requests. In B2B, where there is normally a huge amount of data and a smaller number of customers, the duplication penalty might not be justified.
To address this, you can use the StorageDatabase module, which replaces Redis with a read-only database connection and reduces duplication for large datasets.
For more information, see Bypass the key-value storage.
Manually triggering publish in data import
During data import, an entity is often saved in multiple stages. In the following example, an entity is saved three times:
-
To generate a unique identifier
-
To save dependent entities using the identifier
-
To save the main entity with the complete data
If you rely on automatic event triggering in this scenario, the publish event for the main entity may be processed multiple times, which can lead to redundant operations or data inconsistencies.
To avoid this issue, you can disable automatic event triggering and trigger the publish event manually after the full entity data is saved:
$this->eventFacade->trigger($eventName, TransferInterface $transfer);
This ensures updated data is propagated to all relevant systems. For implementation details, see the following docs:
Troubleshooting failed messages in error queues
During high-volume operations or parallel data import, some messages may fail and be redirected to error queues. This is commonly caused by exceeding the maximum message size or not meeting data dependencies.

Monitoring error queues is critical for identifying and resolving synchronization issues. For more details, see Messages are moved to error queues.
Messages stuck without errors
Messages remain in the Ready state and are not processed, even though no errors appear in CloudWatch
This may indicate that the responsible queue worker has stopped or the queue is misconfigured.
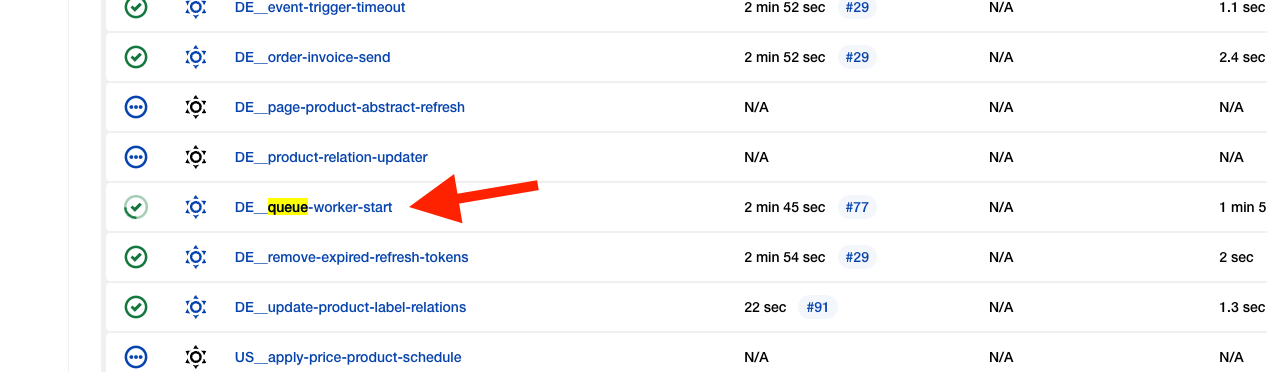
Review the queue status and ensure that the worker is running. For troubleshooting, see Messages are stuck without error notifications.
Messages in unacknowledged state
If messages are stuck in the Unacknowledged (Unacked) state, they may not be fully consumed or the worker may be encountering issues mid-processing.
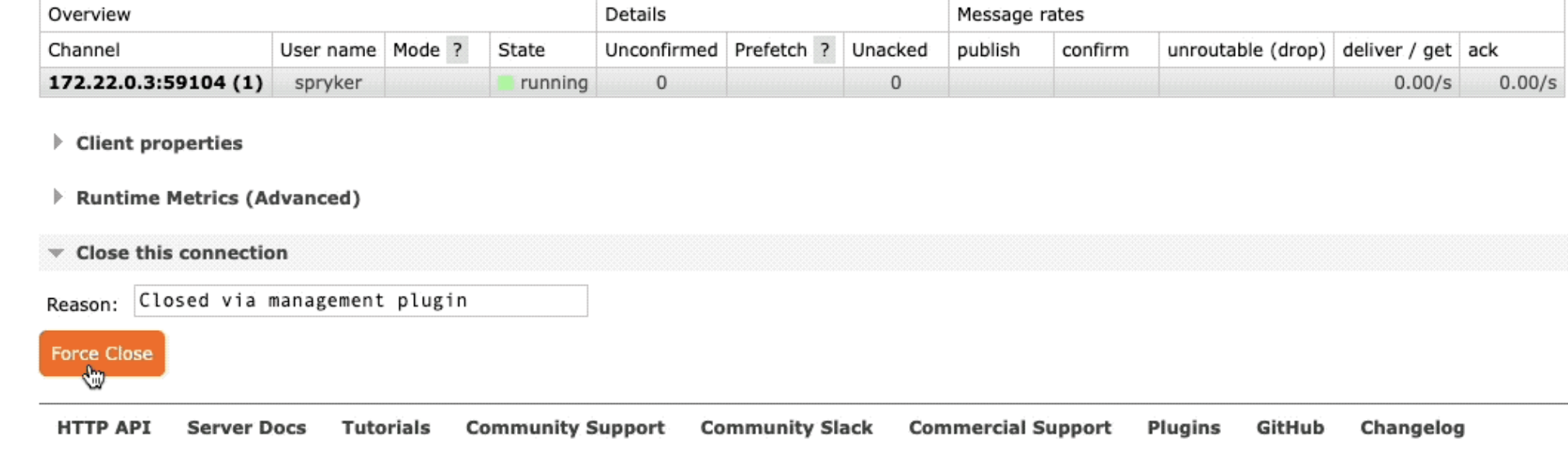
Investigate worker logs and system resource usage to resolve this. For troubleshooting, see Messages are stuck in the Unacked state.
Disabling RabbitMQ consumers
To temporarily stop queue processing - for maintenance, debugging, or system updates - you can disable RabbitMQ consumers by turning off the associated Jenkins jobs.
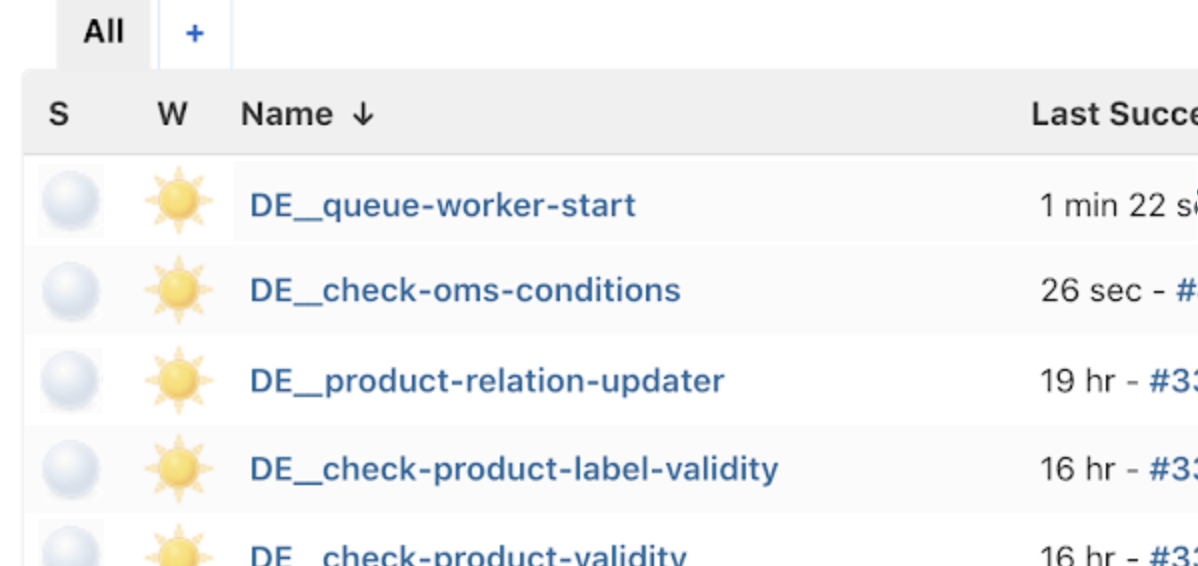
For more information, see the following docs:
Adding more event listeners
When building features like customer notifications, use event subscribers rather than embedding listeners in product modules. This allows for centralized listener management and easier maintenance and scaling.
Register your subscriber in the EventDependencyProvider to activate it. For instructions, see Listen to events.
Accessing all queues
After a large import, re-sync, or during troubleshooting, it can be helpful to view all queues at once and monitor their consumption and any errors.
To inspect queues, open RabbitMQ in your browser and log in with your credentials. RabbitMQ address is http://queue.<context>.local:15672/.
Replace <context> with demoshop, suite, b2b, b2c, spryker based on your environment.
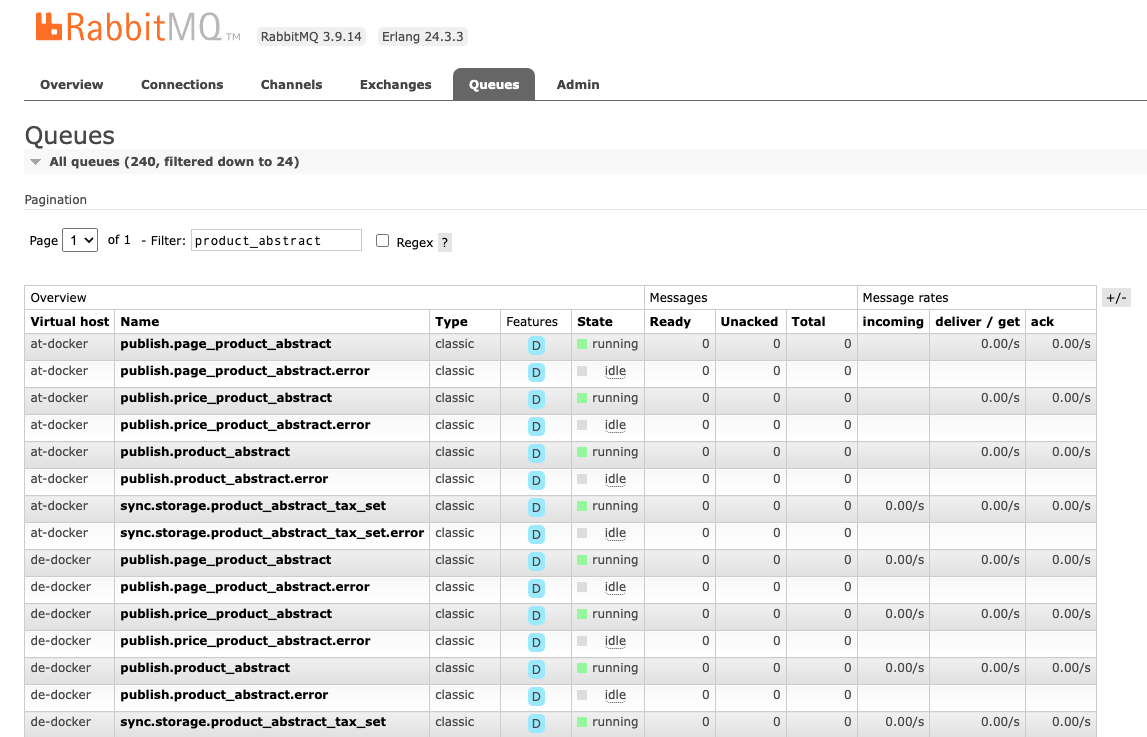
For more information on queues, see Queue.
Reducing the number of emitted events
Emitting too many events can result in unnecessary duplication and performance issues. To reduce event load:
Ensure that a single publish event is emitted for each create or update operation, such as creating or updating the product.
In bulk operations, trigger publish events only once, after the final batch operation.
This minimizes overhead and keeps event processing efficient.
Thank you!
For submitting the form