Publish and Synchronization
Edit on GitHubTo serve data quickly, your shop application reads from Redis (key–value storage) and Elasticsearch (search and analytics). The client doesn’t access the primary SQL database directly. Instead, Spryker uses the Publish and Synchronize (P&S) mechanism to move data from the relational database to Redis and Elasticsearch.
P&S denormalizes and distributes data to achieve the following:
-
Reduce the load on the master database.
-
Deliver localized data, such as pricing, availability, and product details, in a format prepared for the Storefront.
-
Run queries, which improves Storefront performance.
Benefits of P&S:
-
Near real-time updates because empty queues are checked every second by default.
-
Batched SQL queries during publishing for better performance.
-
Incremental exports; full re-exports are not needed.
-
Safe fallback: the SQL database always holds the source of truth. You can re-sync at any time.
-
Store- and locale-specific data support.
-
Spryker relies on Propel behaviors to fire events automatically whenever you save, update, or delete an entity. So you don’t need to call any P&S code manually.
P&S process
P&S process schema:
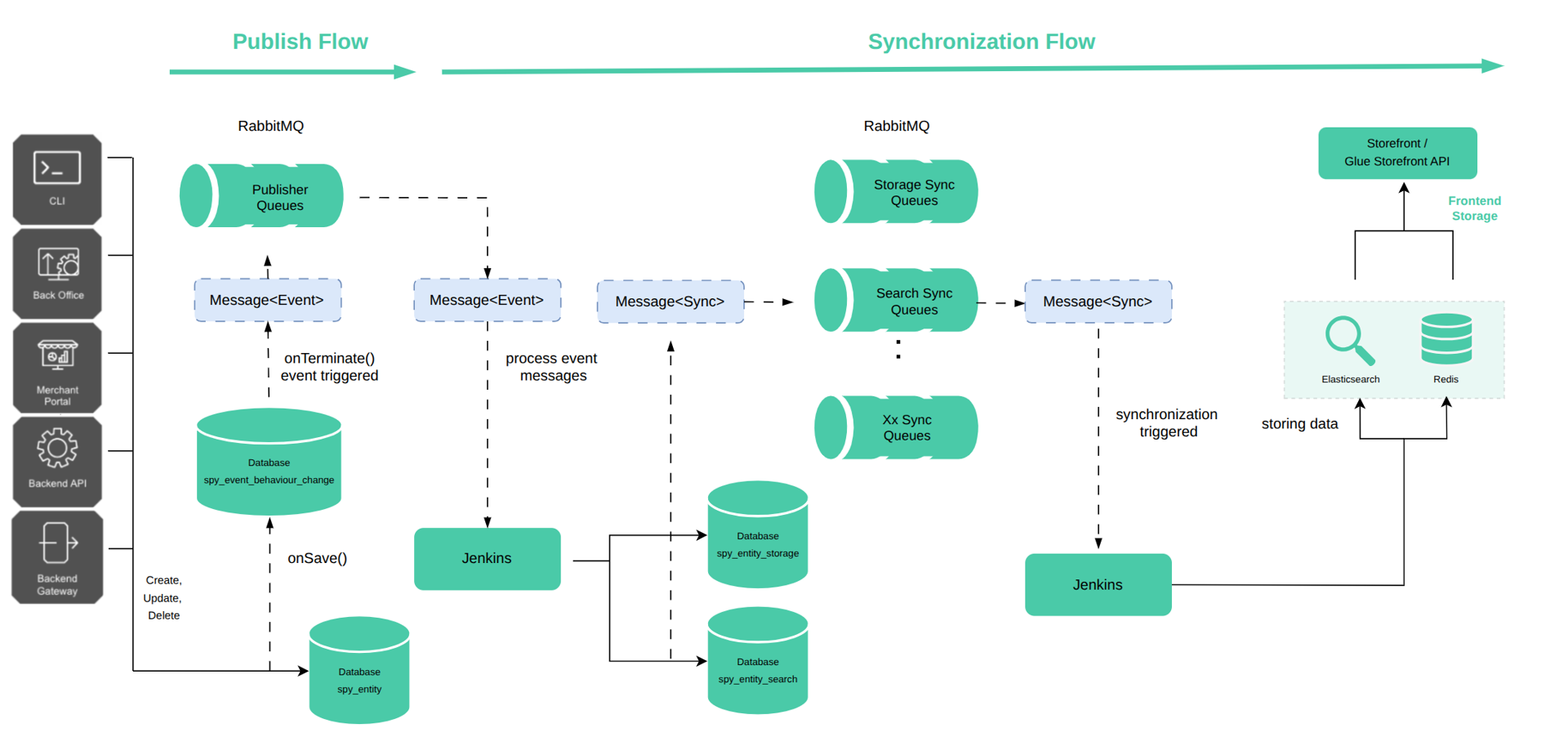
─────────▶ (solid): Synchronous call or direct write
-
-
-
- -▶ (dashed): Asynchronous event, queue, or deferred processing
-
-
1. Publish
You can start the publish process using automated or manual event triggering.
Automated event triggering
When an entity implements Propel Event behavior, every create, update, or delete operation automatically triggers a corresponding publish event. This behavior ensures that entity changes are immediately captured and propagated through the system.
For example, saving an abstract product triggers a create abstract product event:
$productAbstractEntity = SpyProductAbstractQuery::create()->findOne();
$productAbstractEntity->setColorCode("#FFFFFF");
$productAbstractEntity->save();
Calling save(), the entity invokes the saveEventBehaviorEntityChange() method, which creates a SpyEventBehaviorEntityChange record. This record is saved into the database and remains pending until the onTerminate Symfony event is triggered. During the onTerminate event, all SpyEventBehaviorEntityChange entries, produced by the current process, are dispatched into the corresponding message queues.
The event dispatcher plugin responsible for this behavior is Spryker\Zed\EventBehavior\Communication\Plugin\EventDispatcher\EventBehaviorEventDispatcherPlugin.
If the process finishes early, and events are not processed during runtime, they’re handled automatically by the command in Jenkins:
vendor/bin/console event:trigger:timeout
This command is executed every five minutes by default.
Manual event triggering
You can trigger the publish event manually using the event facade:
$this->eventFacade->trigger(CmsStorageConfig::CMS_KEY_PUBLISH_WRITE, (new EventEntityTransfer())->setId($id));
Manual event triggering works best when an entity passes several stages before it becomes available to customers. The typical use case is content management or data import. For example, when you create a page, it usually remains a draft until you decide to publish it, or when you release a new product to the market.
Event in the queue
When the publish process is triggered, one or more event messages are posted to queues. Each message includes metadata about the event that triggered it:
-
Event name
-
The affected entity’s ID
-
Names of the corresponding publisher and transfer classes
-
A list of modified columns
-
Foreign keys used to trace back the updated Propel entities
The message doesn’t include the actual changed data because the data might change before the event is being processed.
Example:
{
"listenerClassName":"Spryker\\Zed\\UrlStorage\\Communication\\Plugin\\Event\\Listener\\UrlStorageListener",
"transferClassName":"Generated\\Shared\\Transfer\\EventEntityTransfer",
"transferData":{
"event":"Entity.spy_url.update",
"name":"spy_url",
"id":488,
"foreign_keys":{
"spy_url.fk_resource_page":7,
"spy_url.fk_resource_product_abstract":null,
"spy_url.fk_resource_redirect":null,
"spy_url.fk_resource_product_set":null,
"spy_url.fk_resource_categorynode":null,
"spy_url.fk_locale":46
},
"modified_columns":[
"spy_url.url"
]
},
"eventName":"Entity.spy_url.update"
}
2. Synchronize
Synchronize is the process of transferring data from the database to a storage, such as Redis and Elasticsearch, making it accessible to fast customer-facing applications.
After a publish event is triggered and a message is placed in a queue (RabbitMQ), the following process takes place:
-
The
vendor/bin/console queue:worker:startcommand, typically executed via Jenkins, scans for all non-empty queues. -
For each non-empty queue, a subprocess is started using the following command:
vendor/bin/console queue:task:start {queueName}
{queueName} is the name of the non-empty queue being processed.
-
This command identifies the appropriate listener responsible for processing the messages in this queue.
-
Based on the listener logic, storage or search entities are calculated.
-
These entities are persisted in the database.
Synchronization types
P&S supports two types of synchronization: asynchronous and direct. Their differences are described in the following sections.
Asynchronous synchronization
Asynchronous synchronization provides greater stability, although it may take slightly longer to complete. It works as follows:
-
When a storage or search entity is saved to the database, a new message is generated and placed into a dedicated synchronization queue in RabbitMQ.
-
vendor/bin/console queue:worker:startcommand detects this non-empty queue and spawns a child process using thevendor/bin/console queue:task:start {queueName}command. -
During execution, the message is processed, and the resulting data is stored in Redis or Elasticsearch.
Asynchronous sync is used by default when you implement P&S.
Direct synchronize
Direct synchronize uses in-memory storage to temporarily hold synchronization messages and writes them at the end of the request lifecycle instead of using queues. To improve performance and flexibility, you can enable this method at the project level.
How it works:
-
When a storage or search entity is saved to the database, synchronization messages are stored in the memory of the current PHP process.
-
After the console command completes, Symfony triggers the
onTerminateevent. -
All messages stored in memory are written directly to Redis and/or Elasticsearch.
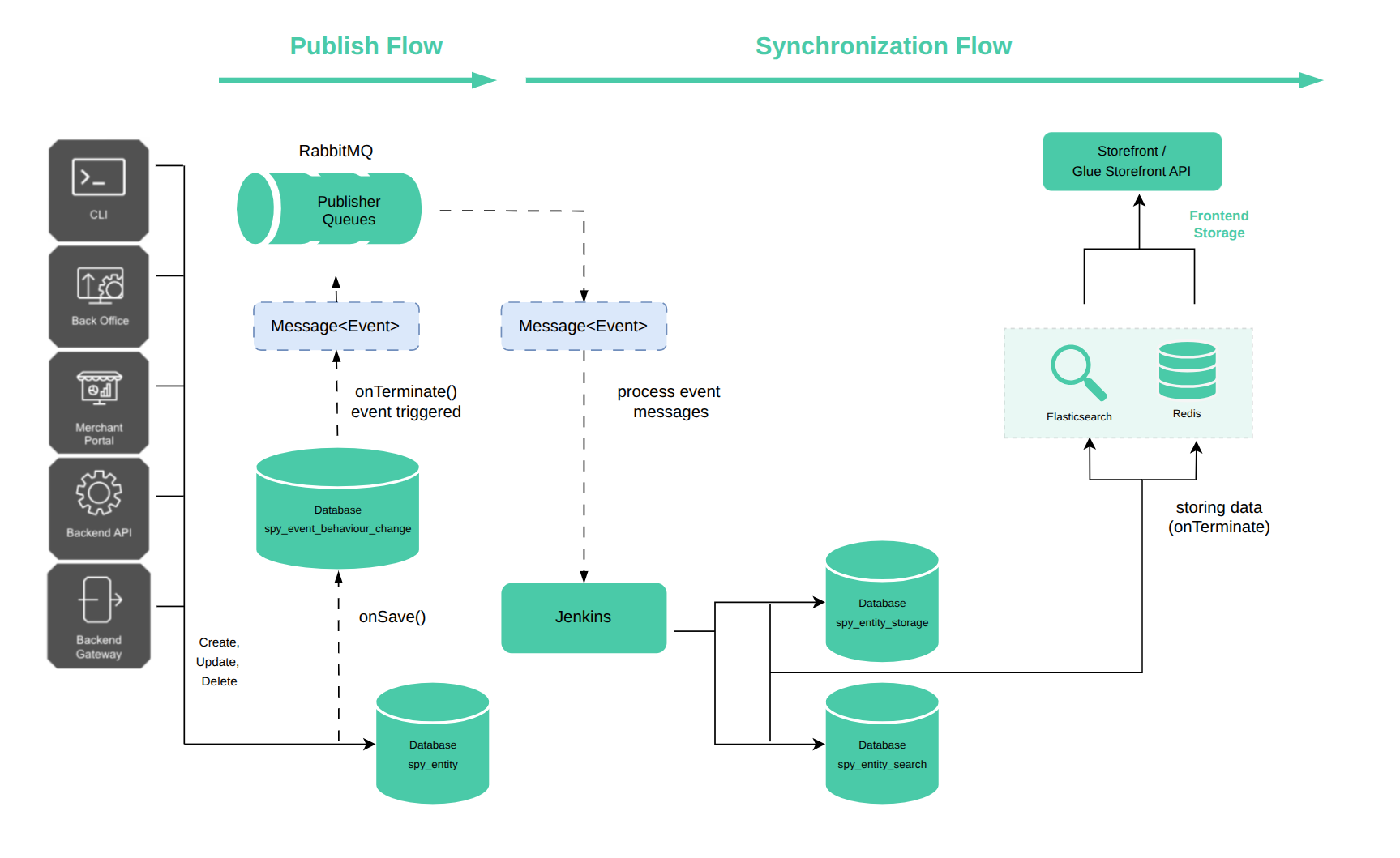
─────────▶ (solid): Synchronous call or direct write
-
-
-
- -▶ (dashed): Asynchronous event, queue, or deferred processing
-
-
For instructions on configuring direct sync, see Configure direct synchronize.
Key differences from asynchronous synchronization
| Aspect | Asynchronous Sync | Direct Sync |
|---|---|---|
| Message queue | Required | Skipped |
| Processing delay | Delay is caused by queuing and worker execution. | Processed after the command ends without a delay. |
| Performance impact | Slower during command execution because of additional processing steps. | Faster during command execution. |
| Use case | Default; scalable for large data volumes. | Optimized for speed and reduced infrastructure overhead; performs better with low data volumes. |
Asynchronous synchronization is more stable, easier to handle errors, and works with bigger amounts of data.
Direct synchronization provides faster results, and is particularly useful for the following use cases:
-
Test environments
-
Small projects
-
Performance-critical operations where immediate consistency is preferred
P&S process example
The following walkthrough shows how the P&S mechanism moves product-abstract data from the Spryker backend to Redis and Elasticsearch. The example is based on SpyProductAbstract sync in the B2B Marketplace Demo Shop.
1. Publish
When you save a SpyProductAbstract entity in the Back Office - such as clicking Save on a product page - Spryker immediately triggers the P&S workflow. In this example, the product is enabled in two stores:
During the save operation, Spryker generates multiple events called messages and places them in RabbitMQ.
2. Synchronize
RabbitMQ now contains several events that relate to the product abstract and its dependent entities–for example, product concrete, URL storage, and price.
Asynchronous synchronization
Storage events
-
Queue:
publish.product_abstractreceives a storage event. -
Listener:
ProductAbstractStoragePublishListener(registered inProductStorageEventSubscriber.php) consumes the event. This message contains only metadata. The actual payload is constructed later by the storage or search listeners.
Event example:
{
"listenerClassName": "Spryker\\Zed\\ProductStorage\\Communication\\Plugin\\Event\\Listener\\ProductAbstractStoragePublishListener",
"transferClassName": "Generated\\Shared\\Transfer\\EventEntityTransfer",
"transferData": {
"additional_values": [],
"id": 416,
"foreign_keys": {
"spy_product_abstract.fk_tax_set": 1
},
"modified_columns": [
"spy_product_abstract.approval_status"
],
"event": "Entity.spy_product_abstract.update",
"name": "spy_product_abstract",
"original_values": []
},
"eventName": "Entity.spy_product_abstract.update"
}
- The listener does the following processing:
- Creates a
SpyProductAbstractStorageentity - Populates the entity with the data that will be used on the frontend
- Saves the data to the
spy_product_abstract_storagetable, one row per store and locale
- Creates a

- Follow-up event: The listener sends a new message to the
sync.storage.productqueue.
Message example:
{
"listenerClassName": "Spryker\\Zed\\ProductStorage\\Communication\\Plugin\\Event\\Listener\\ProductAbstractStoragePublishListener",
"transferClassName": "Generated\\Shared\\Transfer\\EventEntityTransfer",
"transferData": {
"additional_values": [],
"id": 416,
"foreign_keys": {
"spy_product_abstract.fk_tax_set": 1
},
"modified_columns": [
"spy_product_abstract.approval_status"
],
"event": "Entity.spy_product_abstract.update",
"name": "spy_product_abstract",
"original_values": []
},
"eventName": "Entity.spy_product_abstract.update"
}
-
Worker: Jenkins launches
vendor/bin/console queue:worker:start, which invokesSynchronizationFacade::processStorageMessages(). -
Result: All storage messages are written to Redis.
Search event
-
Queue:
publish.page_product_abstractreceives a search event. -
Listener:
ProductPageProductAbstractPublishListener(registered inProductPageSearchEventSubscriber.php) consumes the message.
Message example:
{
"listenerClassName": "Spryker\\Zed\\ProductStorage\\Communication\\Plugin\\Event\\Listener\\ProductAbstractStoragePublishListener",
"transferClassName": "Generated\\Shared\\Transfer\\EventEntityTransfer",
"transferData": {
"additional_values": [],
"id": 416,
"foreign_keys": {
"spy_product_abstract.fk_tax_set": 1
},
"modified_columns": [
"spy_product_abstract.approval_status"
],
"event": "Entity.spy_product_abstract.update",
"name": "spy_product_abstract",
"original_values": []
},
"eventName": "Entity.spy_product_abstract.update"
}
- The listener does the following processing:
- Creates a
SpyProductAbstractPageSearchentity - Populates the entity with data
- Saves the entity to the
spy_product_abstract_page_searchtable, one row per store and locale
- Creates a

-
Follow-up event: The listener sends a new message to the
sync.search.productqueue. -
Worker: Jenkins launches
vendor/bin/console queue:worker:start, which invokesSynchronizationFacade::processSearchMessages(). -
Result: All search messages are indexed in Elasticsearch.
By following this workflow, Spryker makes all product changes made in the Back Office available in Redis and Elasticsearch with minimal delay, even across multiple stores and locales.
Direct synchronization
In direct synchronization mode, the behavior of entities, such as SpyProductAbstractPageSearch and SpyProductAbstractStorage, changes. Instead of sending messages to the queue for later processing as described in steps 3–5 of the previous example, these entities are written directly to Redis or Elasticsearch during the same PHP process.
This approach uses DirectSynchronizationConsolePlugin, which leverages Symfony’s onTerminate event to perform the final synchronization step after the console command completes execution.
For details on configuring direct sync, see Configure direct synchronize.
Data architecture
P&S supports intelligent solutions and scalable architecture designs by handling data denormalization and distribution across Spryker Storefronts and APIs.
Denormalization and distribution
-
Denormalization prepares data in the format required by the consuming clients, such as storefronts or APIs.
-
Distribution ensures that this data is moved closer to end users, enabling fast and responsive access that feels like interacting with a local store.
Project examples of data denormalization and distribution
Several Spryker partners leverage P&S to distribute product data to warehouse picking devices, such as barcode scanners. These devices access the product catalog as if it were local, allowing them to function even with poor or no network connectivity.
In other implementations, P&S enables businesses to centralize sensitive customer data - such as in Germany for compliance reasons - while distributing localized catalogs globally. For example, buyers in Brazil can browse the catalog with minimal latency, as if the data were hosted locally.
Architectural considerations
When designing a solution that incorporates P&S, consider the following:
-
Eventual consistency of data in storefronts and client applications
-
Horizontal scalability of the publish process (supported natively) and the synchronization process (may require custom development)
-
Data object limitations, including payload sizes and system constraints
Data object limitations
To ensure system stability, it’s critical to define and enforce appropriate non-functional requirements for P&S, such as the following:
-
The maximum size of a storage synchronization message should not exceed 256 KB. This prevents processing issues and ensures that API consumers can reliably receive data without encountering failures because of large payloads.
-
Avoid exceeding request limits for storage, such as Redis, and search systems, such as OpenSearch, during the synchronization process.
As with any non-functional requirements, you can adapt these constraints based on project needs. However, this may require a custom implementation or refactoring Spryker’s default functionality.
For example, if your project must support sending API payloads larger than 10 MB - an uncommon scenario for e-commerce platforms - it’s still achievable with Spryker. However, this requires a thorough review of the business logic tied to the relevant API endpoints and adjustments to support larger objects.
Thank you!
For submitting the form